Custom Encoder: Rule-Based
Lightwood uses “Encoders” to convert preprocessed (cleaned) data into features. Encoders represent the feature engineering step of the data science pipeline; they can either have a set of instructions (“rule-based”) or a learned representation (trained on data).
In the following notebook, we will experiment with creating a custom encoder that creates Label Encoding.
For example, imagine we have the following set of categories:
MyColumnData = ["apple", "orange", "orange", "banana", "apple", "dragonfruit"]
There are 4 categories to consider: “apple”, “banana”, “orange”, and “dragonfruit”.
Label encoding allows you to refer to these categories as if they were numbers. For example, consider the mapping (arranged alphabetically):
1 - apple 2 - banana 3 - dragonfruit 4 - orange
Using this mapping, we can convert the above data as follows:
MyFeatureData = [1, 4, 4, 2, 1, 3]
In the following notebook, we will design a LabelEncoder for Lightwood for use on categorical data. We will be using the Kaggle “Used Car” dataset. We’ve provided a link for you to automatically access this CSV. This dataset describes various details of cars on sale - with the goal of predicting how much this car may sell for.
Let’s get started.
[1]:
import pandas as pd
# Lightwood modules
import lightwood as lw
from lightwood import ProblemDefinition, \
JsonAI, \
json_ai_from_problem, \
code_from_json_ai, \
predictor_from_code
INFO:lightwood-3462:No torchvision detected, image helpers not supported.
INFO:lightwood-3462:No torchvision/pillow detected, image encoder not supported
1) Load your data
Lightwood works with pandas.DataFrames; load data via pandas as follows:
[2]:
filename = 'https://raw.githubusercontent.com/mindsdb/benchmarks/main/benchmarks/datasets/used_car_price/data.csv'
df = pd.read_csv(filename)
df.head()
[2]:
| model | year | price | transmission | mileage | fuelType | tax | mpg | engineSize | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | A1 | 2017 | 12500 | Manual | 15735 | Petrol | 150 | 55.4 | 1.4 |
| 1 | A6 | 2016 | 16500 | Automatic | 36203 | Diesel | 20 | 64.2 | 2.0 |
| 2 | A1 | 2016 | 11000 | Manual | 29946 | Petrol | 30 | 55.4 | 1.4 |
| 3 | A4 | 2017 | 16800 | Automatic | 25952 | Diesel | 145 | 67.3 | 2.0 |
| 4 | A3 | 2019 | 17300 | Manual | 1998 | Petrol | 145 | 49.6 | 1.0 |
We can see a handful of columns above, such as model, year, price, transmission, mileage, fuelType, tax, mpg, engineSize. Some columns are numerical whereas others are categorical. We are going to specifically only focus on categorical columns.
2) Generate JSON-AI Syntax
We will make a LabelEncoder as follows:
Find all unique examples within a column
Order the examples in a consistent way
Label (python-index of 0 as start) each category
Assign the label according to each datapoint.
First, let’s generate a JSON-AI syntax so we can automatically identify each column.
[3]:
# Create the Problem Definition
pdef = ProblemDefinition.from_dict({
'target': 'price', # column you want to predict
#'ignore_features': ['year', 'mileage', 'tax', 'mpg', 'engineSize']
})
# Generate a JSON-AI object
json_ai = json_ai_from_problem(df, problem_definition=pdef)
INFO:type_infer-3462:Analyzing a sample of 6920
INFO:type_infer-3462:from a total population of 10668, this is equivalent to 64.9% of your data.
INFO:type_infer-3462:Using 3 processes to deduct types.
INFO:type_infer-3462:Infering type for: year
INFO:type_infer-3462:Infering type for: price
INFO:type_infer-3462:Infering type for: model
INFO:type_infer-3462:Column year has data type integer
INFO:type_infer-3462:Column price has data type integer
INFO:type_infer-3462:Infering type for: transmission
INFO:type_infer-3462:Infering type for: mileage
INFO:type_infer-3462:Column mileage has data type integer
INFO:type_infer-3462:Infering type for: fuelType
INFO:type_infer-3462:Column model has data type categorical
INFO:type_infer-3462:Infering type for: tax
INFO:type_infer-3462:Column tax has data type integer
INFO:type_infer-3462:Infering type for: mpg
INFO:type_infer-3462:Column mpg has data type float
INFO:type_infer-3462:Infering type for: engineSize
INFO:type_infer-3462:Column engineSize has data type float
INFO:type_infer-3462:Column fuelType has data type categorical
INFO:type_infer-3462:Column transmission has data type categorical
INFO:dataprep_ml-3462:Starting statistical analysis
INFO:dataprep_ml-3462:Finished statistical analysis
Let’s take a look at our JSON-AI and print to file.
[4]:
print(json_ai.to_json())
{
"encoders": {
"price": {
"module": "NumericEncoder",
"args": {
"is_target": "True",
"positive_domain": "$statistical_analysis.positive_domain"
}
},
"model": {
"module": "CategoricalAutoEncoder",
"args": {
"stop_after": "$problem_definition.seconds_per_encoder"
}
},
"year": {
"module": "NumericEncoder",
"args": {}
},
"transmission": {
"module": "OneHotEncoder",
"args": {}
},
"mileage": {
"module": "NumericEncoder",
"args": {}
},
"fuelType": {
"module": "OneHotEncoder",
"args": {}
},
"tax": {
"module": "NumericEncoder",
"args": {}
},
"mpg": {
"module": "NumericEncoder",
"args": {}
},
"engineSize": {
"module": "NumericEncoder",
"args": {}
}
},
"dtype_dict": {
"model": "categorical",
"year": "integer",
"price": "integer",
"transmission": "categorical",
"mileage": "integer",
"fuelType": "categorical",
"tax": "integer",
"mpg": "float",
"engineSize": "float"
},
"dependency_dict": {},
"model": {
"module": "BestOf",
"args": {
"submodels": [
{
"module": "Neural",
"args": {
"fit_on_dev": true,
"stop_after": "$problem_definition.seconds_per_mixer",
"search_hyperparameters": true
}
},
{
"module": "XGBoostMixer",
"args": {
"stop_after": "$problem_definition.seconds_per_mixer",
"fit_on_dev": true
}
},
{
"module": "Regression",
"args": {
"stop_after": "$problem_definition.seconds_per_mixer"
}
},
{
"module": "RandomForest",
"args": {
"stop_after": "$problem_definition.seconds_per_mixer",
"fit_on_dev": true
}
}
]
}
},
"problem_definition": {
"target": "price",
"pct_invalid": 2,
"unbias_target": true,
"seconds_per_mixer": 21384.0,
"seconds_per_encoder": 85536.0,
"expected_additional_time": 11.070627927780151,
"time_aim": 259200,
"target_weights": null,
"positive_domain": false,
"timeseries_settings": {
"is_timeseries": false,
"order_by": null,
"window": null,
"group_by": null,
"use_previous_target": true,
"horizon": null,
"historical_columns": null,
"target_type": "",
"allow_incomplete_history": true,
"eval_incomplete": false,
"interval_periods": []
},
"anomaly_detection": false,
"use_default_analysis": true,
"embedding_only": false,
"dtype_dict": {},
"ignore_features": [],
"fit_on_all": true,
"strict_mode": true,
"seed_nr": 1
},
"identifiers": {},
"imputers": [],
"accuracy_functions": [
"r2_score"
]
}
3) Create your custom encoder (LabelEncoder).
Once our JSON-AI is filled, let’s make our LabelEncoder. All Lightwood encoders inherit from the BaseEncoder class, found here.
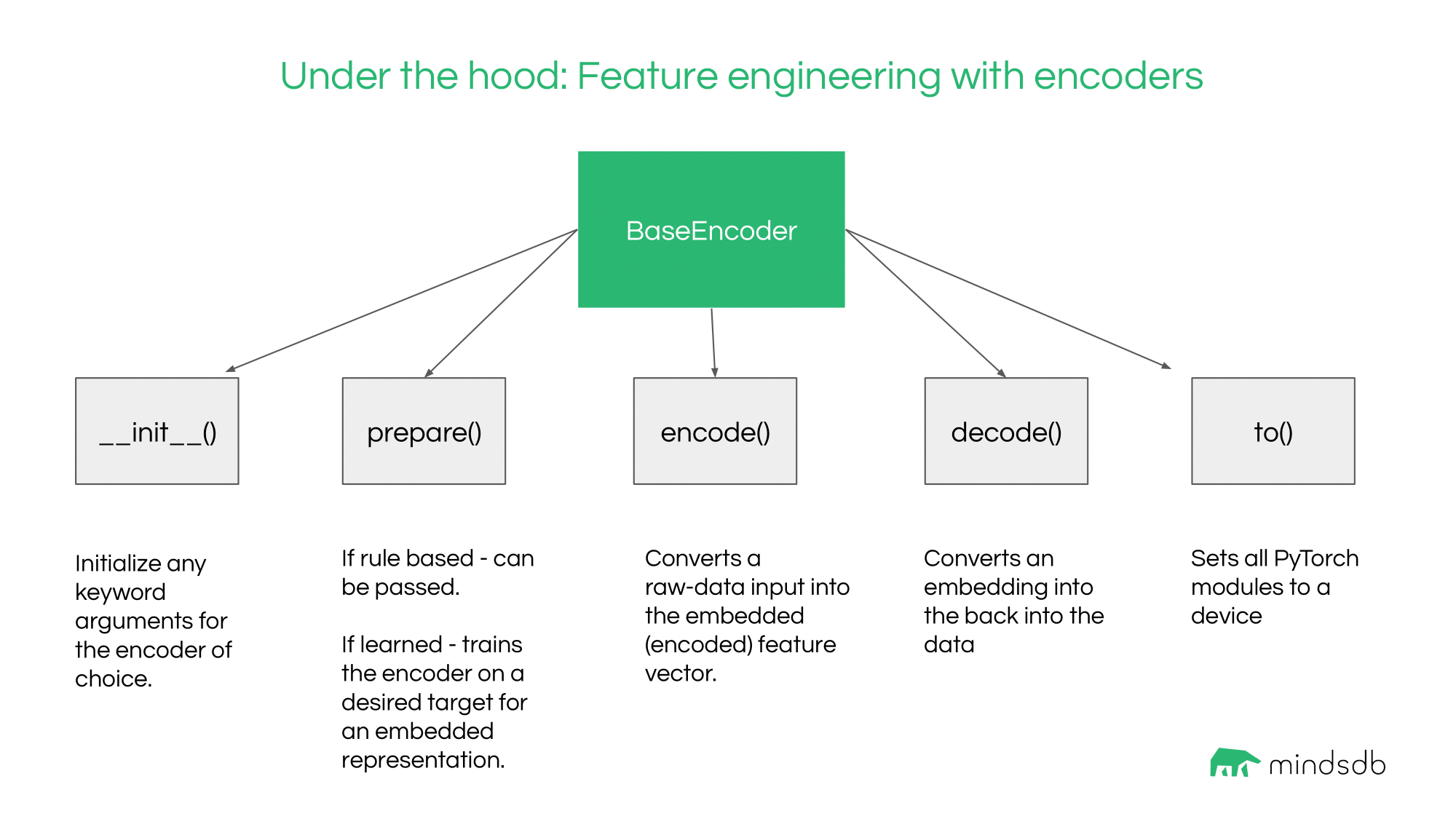
The BaseEncoder has 5 expected calls:
__init__: instantiate the encoderprepare: Train or create the rules of the encoderencode: Given data, convert to the featurized representationdecode: Given featurized representations, revert back to datato: Use CPU/GPU (mostly important for learned representations)
From above, we see that “model”, “transmission”, and “fuelType” are all categorical columns. These will be the ones we want to modify.
LabelEncoder
The LabelEncoder should satisfy a couple of rules
For the
__init__call:
Specify the only argument
is_target; this asks whether the encoder aims to represent the target column.Set
is_prepared=Falsein the initialization. All encoders are prepared using theirprepare()call, which turns this flag on toTrueif preparation of the encoders is successful.Set
output_size=1; the output size refers to how many options the represented encoder may adopt.
For the
preparecall:
Specify the only argument
priming_data; this provides thepd.Seriesof the data column for the encoder.Find all unique categories in the column data
Make a dictionary representing label number to category (reserves 0 as Unknown) and the inverse dictionary
Set
is_prepared=True
The
encode()call will convert each data point’s category name into the encoded label.The
decode()call will convert a previously encoded label into the original category name.
Given this approach only uses simple dictionaries, there is no need for a dedicated to() call (although this would inherit BaseEncoder’s implementation).
This implementation would look as follows:
[5]:
%%writefile LabelEncoder.py
"""
2021.10.13
Create a LabelEncoder that transforms categorical data into a label.
"""
import pandas as pd
import torch
from lightwood.encoder import BaseEncoder
from typing import List, Union
from lightwood.helpers.log import log
class LabelEncoder(BaseEncoder):
"""
Create a label representation for categorical data. The data will rely on sorted to organize the order of the labels.
Class Attributes:
- is_target: Whether this is used to encode the target
- is_prepared: Whether the encoder rules have been set (after ``prepare`` is called)
""" # noqa
is_target: bool
is_prepared: bool
is_timeseries_encoder: bool = False
is_trainable_encoder: bool = True
def __init__(self, is_target: bool = False, stop_after = 10) -> None:
"""
Initialize the Label Encoder
:param is_target:
"""
self.is_target = is_target
self.is_prepared = False
# Size of the output encoded dimension per data point
# For LabelEncoder, this is always 1 (1 label per category)
self.output_size = 1
def prepare(self, train_data: pd.Series, dev_data: pd.Series) -> None:
"""
Create a LabelEncoder for categorical data.
LabelDict creates a mapping where each index is associated to a category.
:param priming_data: Input column data that is categorical.
:returns: Nothing; prepares encoder rules with `label_dict` and `ilabel_dict`
"""
# Find all unique categories in the dataset
categories = train_data.unique()
log.info("Categories Detected = " + str(self.output_size))
# Create the Category labeller
self.label_dict = {"Unknown": 0} # Include an unknown category
self.label_dict.update({cat: idx + 1 for idx, cat in enumerate(categories)})
self.ilabel_dict = {idx: cat for cat, idx in self.label_dict.items()}
self.is_prepared = True
def encode(self, column_data: Union[pd.Series, list]) -> torch.Tensor:
"""
Convert pre-processed data into the labeled values
:param column_data: Pandas series to convert into labels
"""
if isinstance(column_data, pd.Series):
enc = column_data.apply(lambda x: self.label_dict.get(x, 0)).tolist()
else:
enc = [self.label_dict.get(x, 0) for x in column_data]
return torch.Tensor(enc).int().unsqueeze(1)
def decode(self, encoded_data: torch.Tensor) -> List[object]:
"""
Convert torch.Tensor labels into categorical data
:param encoded_data: Encoded data in the form of a torch.Tensor
"""
return [self.ilabel_dict[i.item()] for i in encoded_data]
Writing LabelEncoder.py
Some additional notes:
The
encode()call should be able to intake a list of values, it is optional to make it compatible withpd.Seriesorpd.DataFrameThe output of
encode()must be a torch tensor with dimensionality \(N_{rows} x N_{output}\).
Now that the LabelEncoder is complete, move this to ~/lightwood_modules and we’re ready to try this out!
[6]:
from lightwood import load_custom_module
load_custom_module('LabelEncoder.py')
4) Edit JSON-AI
Now that we have our LabelEncoder script, we have two ways of introducing this encoder:
Change all categorical columns to our encoder of choice
Replace the default encoder (
Categorical.OneHotEncoder) for categorical data to our encoder of choice
In the first scenario, we may not want to change ALL columns. By switching the encoder on a Feature level, Lightwood allows you to control how representations for a given feature are handled. However, suppose you want to replace an approach entirely with your own methodology - Lightwood supports overriding default methods to control how you want to treat a data type as well.
Below, we’ll show both strategies:
The first strategy requires just specifying which features you’d like to change. Once you have your list, you can manually set the encoder “module” to the class you’d like. This is best suited for a few columns or if you only want to override a few particular columns as opposed to replacing the ``Encoder`` behavior for an entire data type. #### Strategy 1: Change the encoders for the features directly
for ft in ["model", "transmission", "fuelType"]: # Features you want to replace
# Set each feature to the custom encoder
json_ai.encoders[ft]['module'] = 'LabelEncoder.LabelEncoder'
Suppose you have many columns that are categorical- you may want to enforce your approach explicitly without naming each column. This can be done by examining the data_dtype of JSON-AI’s features. For all features that are type categorical (while this is a str, it’s ideal to import dtype and explicitly check the data type), replace the default Encoder with your encoder. In this case, this is LabelEncoder.LabelEncoder. #### Strategy 2: Programatically change all encoder
assignments for a data type
from lightwood.api import dtype
for i in json_ai.dtype_dict:
if json_ai.dtype_dict[i] == dtype.categorical:
json_ai.encoders[i]['module'] = 'LabelEncoder.LabelEncoder'
We’ll go with the first approach for simplicity:
[7]:
for ft in ["model", "transmission", "fuelType"]: # Features you want to replace
# Set each feature to the custom encoder
json_ai.encoders[ft]['module'] = 'LabelEncoder.LabelEncoder'
5) Generate code and your predictor from JSON-AI
Now, let’s use this JSON-AI object to generate code and make a predictor. This can be done in 2 simple lines, below:
[8]:
#Generate python code that fills in your pipeline
code = code_from_json_ai(json_ai)
# Turn the code above into a predictor object
predictor = predictor_from_code(code)
Now, let’s run our pipeline. To do so, let’s first:
Perform a statistical analysis on the data (this is important in preparing Encoders/Mixers as it populates the
StatisticalAnalysisattribute with details some encoders need).Clean our data
Prepare the encoders
Featurize the data
[9]:
# Perform Stats Analysis
predictor.analyze_data(df)
# Pre-process the data
cleaned_data = predictor.preprocess(data=df)
# Create a train/test split
split_data = predictor.split(cleaned_data)
# Prepare the encoders
predictor.prepare(split_data)
# Featurize the data
ft_data = predictor.featurize(split_data)
INFO:dataprep_ml-3462:Starting statistical analysis
INFO:dataprep_ml-3462:Finished statistical analysis
DEBUG:lightwood-3462: `analyze_data` runtime: 0.42 seconds
INFO:dataprep_ml-3462:Cleaning the data
DEBUG:lightwood-3462: `preprocess` runtime: 0.13 seconds
INFO:dataprep_ml-3462:Splitting the data into train/test
DEBUG:lightwood-3462: `split` runtime: 0.0 seconds
DEBUG:dataprep_ml-3462:Preparing sequentially...
DEBUG:dataprep_ml-3462:Preparing encoder for year...
DEBUG:dataprep_ml-3462:Preparing encoder for mileage...
DEBUG:dataprep_ml-3462:Preparing encoder for tax...
DEBUG:dataprep_ml-3462:Preparing encoder for mpg...
DEBUG:dataprep_ml-3462:Preparing encoder for engineSize...
INFO:lightwood-3462:Categories Detected = 1
INFO:lightwood-3462:Categories Detected = 1
INFO:lightwood-3462:Categories Detected = 1
DEBUG:lightwood-3462: `prepare` runtime: 0.01 seconds
INFO:dataprep_ml-3462:Featurizing the data
DEBUG:lightwood-3462: `featurize` runtime: 0.55 seconds
The splitter creates 3 data-splits, a “train”, “dev”, and “test” set. The featurize command from the predictor allows us to convert the cleaned data into features. We can access this as follows:
[10]:
# Pick a categorical column name
col_name = "fuelType"
# Get the encoded feature data
enc_ft = ft_data["train"].get_encoded_column_data(col_name).squeeze(1) #torch tensor (N_rows x N_output_dim)
# Get the original data from the dataset
orig_data = ft_data["train"].get_column_original_data(col_name) #pandas dataframe
# Create a pandas data frame to compare encoded data and original data
compare_data = pd.concat([orig_data, pd.Series(enc_ft, name="EncData")], axis=1)
compare_data.head()
[10]:
| fuelType | EncData | |
|---|---|---|
| 0 | Diesel | 1.0 |
| 1 | Diesel | 1.0 |
| 2 | Diesel | 1.0 |
| 3 | Petrol | 2.0 |
| 4 | Diesel | 1.0 |
We can see what the label mapping is by inspecting our encoders as follows:
[11]:
# Label Name -> Label Number
print(predictor.encoders[col_name].label_dict)
{'Unknown': 0, 'Diesel': 1, 'Petrol': 2, 'Hybrid': 3}
For each category above, the number associated in the dictionary is the label for each category. This means “Diesel” is always represented by a 1, etc.
With that, you’ve created your own custom Encoder that uses a rule-based approach! Please checkout more tutorials for other custom approach guides.