Tutorial - Time series forecasting
Introduction
Time series are an ubiquitous type of data in all types of processes. Producing forecasts for them can be highly valuable in domains like retail or industrial manufacture, among many others.
Lightwood supports time series forecasting (both univariate and multivariate inputs), handling many of the pain points commonly associated with setting up a manual time series predictive pipeline.
In this tutorial, we will train a lightwood predictor and analyze its forecasts for the task of counting sunspots in monthly intervals.
Load data
Let’s begin by loading the dataset and looking at it:
[1]:
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/mindsdb/benchmarks/main/benchmarks/datasets/monthly_sunspots/data.csv")
df
[1]:
| Month | Sunspots | |
|---|---|---|
| 0 | 1749-01 | 58.0 |
| 1 | 1749-02 | 62.6 |
| 2 | 1749-03 | 70.0 |
| 3 | 1749-04 | 55.7 |
| 4 | 1749-05 | 85.0 |
| ... | ... | ... |
| 2815 | 1983-08 | 71.8 |
| 2816 | 1983-09 | 50.3 |
| 2817 | 1983-10 | 55.8 |
| 2818 | 1983-11 | 33.3 |
| 2819 | 1983-12 | 33.4 |
2820 rows × 2 columns
This is a very simple dataset. It’s got a single column that specifies the month in which the measurement was done, and then in the ‘Sunspots’ column we have the actual quantity we are interested in forecasting. As such, we can characterize this as a univariate time series problem.
Define the predictive task
We will use Lightwood high level methods to state what we want to predict. As this is a time series task (because we want to leverage the notion of time to predict), we need to specify a set of arguments that will activate Lightwood’s time series pipeline:
[2]:
from lightwood.api.high_level import ProblemDefinition
INFO:lightwood-3258:No torchvision detected, image helpers not supported.
INFO:lightwood-3258:No torchvision/pillow detected, image encoder not supported
[3]:
tss = {'horizon': 6, # the predictor will learn to forecast what the next semester counts will look like (6 data points at monthly intervals -> 6 months)
'order_by': 'Month', # what column is used to order the entire datset
'window': 12 # how many past values to consider for emitting predictions
}
pdef = ProblemDefinition.from_dict({'target': 'Sunspots', # specify the column to forecast
'timeseries_settings': tss # pass along all time series specific parameters
})
Now, let’s do a very simple train-test split, leaving 10% of the data to check the forecasts that our predictor will produce:
[4]:
cutoff = int(len(df)*0.9)
train = df[:cutoff]
test = df[cutoff:]
print(train.shape, test.shape)
(2538, 2) (282, 2)
Generate the predictor object
Now, we can generate code for a machine learning model by using our problem definition and the data:
[5]:
from lightwood.api.high_level import (
json_ai_from_problem,
code_from_json_ai,
predictor_from_code
)
json_ai = json_ai_from_problem(df, problem_definition=pdef)
code = code_from_json_ai(json_ai)
predictor = predictor_from_code(code)
# uncomment this to see the generated code:
# print(code)
INFO:type_infer-3258:Analyzing a sample of 2467
INFO:type_infer-3258:from a total population of 2820, this is equivalent to 87.5% of your data.
INFO:type_infer-3258:Infering type for: Month
INFO:type_infer-3258:Column Month has data type date
INFO:type_infer-3258:Infering type for: Sunspots
INFO:type_infer-3258:Column Sunspots has data type float
INFO:dataprep_ml-3258:Starting statistical analysis
/opt/hostedtoolcache/Python/3.9.21/x64/lib/python3.9/site-packages/dataprep_ml/cleaners.py:163: UserWarning: The argument 'infer_datetime_format' is deprecated and will be removed in a future version. A strict version of it is now the default, see https://pandas.pydata.org/pdeps/0004-consistent-to-datetime-parsing.html. You can safely remove this argument.
result = pd.to_datetime(element,
INFO:dataprep_ml-3258:Finished statistical analysis
Train
Okay, everything is ready now for our predictor to learn based on the training data we will provide.
Internally, lightwood cleans and reshapes the data, featurizes measurements and timestamps, and comes up with a handful of different models that will be evaluated to keep the one that produces the best forecasts.
Let’s train the predictor. This should take a couple of minutes, at most:
[6]:
predictor.learn(train)
INFO:dataprep_ml-3258:[Learn phase 1/8] - Statistical analysis
INFO:dataprep_ml-3258:Starting statistical analysis
/opt/hostedtoolcache/Python/3.9.21/x64/lib/python3.9/site-packages/dataprep_ml/cleaners.py:163: UserWarning: The argument 'infer_datetime_format' is deprecated and will be removed in a future version. A strict version of it is now the default, see https://pandas.pydata.org/pdeps/0004-consistent-to-datetime-parsing.html. You can safely remove this argument.
result = pd.to_datetime(element,
INFO:dataprep_ml-3258:Finished statistical analysis
DEBUG:lightwood-3258: `analyze_data` runtime: 0.05 seconds
INFO:dataprep_ml-3258:[Learn phase 2/8] - Data preprocessing
INFO:dataprep_ml-3258:Cleaning the data
/opt/hostedtoolcache/Python/3.9.21/x64/lib/python3.9/site-packages/dataprep_ml/cleaners.py:163: UserWarning: The argument 'infer_datetime_format' is deprecated and will be removed in a future version. A strict version of it is now the default, see https://pandas.pydata.org/pdeps/0004-consistent-to-datetime-parsing.html. You can safely remove this argument.
result = pd.to_datetime(element,
INFO:dataprep_ml-3258:Transforming timeseries data
DEBUG:lightwood-3258: `preprocess` runtime: 0.09 seconds
INFO:dataprep_ml-3258:[Learn phase 3/8] - Data splitting
INFO:dataprep_ml-3258:Splitting the data into train/test
DEBUG:lightwood-3258: `split` runtime: 0.0 seconds
INFO:dataprep_ml-3258:[Learn phase 4/8] - Preparing encoders
DEBUG:dataprep_ml-3258:Preparing sequentially...
DEBUG:lightwood-3258: `prepare` runtime: 0.05 seconds
INFO:dataprep_ml-3258:[Learn phase 5/8] - Feature generation
INFO:dataprep_ml-3258:Featurizing the data
DEBUG:lightwood-3258: `featurize` runtime: 0.04 seconds
INFO:dataprep_ml-3258:[Learn phase 6/8] - Mixer training
INFO:dataprep_ml-3258:Training the mixers
WARNING:lightwood-3258:XGBoost running on CPU
WARNING:lightwood-3258:XGBoost running on CPU
WARNING:lightwood-3258:XGBoost running on CPU
WARNING:lightwood-3258:XGBoost running on CPU
WARNING:lightwood-3258:XGBoost running on CPU
WARNING:lightwood-3258:XGBoost running on CPU
/home/runner/work/lightwood/lightwood/lightwood/mixer/neural.py:124: FutureWarning: `torch.cuda.amp.GradScaler(args...)` is deprecated. Please use `torch.amp.GradScaler('cuda', args...)` instead.
scaler = GradScaler()
/opt/hostedtoolcache/Python/3.9.21/x64/lib/python3.9/site-packages/torch/amp/grad_scaler.py:132: UserWarning: torch.cuda.amp.GradScaler is enabled, but CUDA is not available. Disabling.
warnings.warn(
/opt/hostedtoolcache/Python/3.9.21/x64/lib/python3.9/site-packages/pytorch_ranger/ranger.py:172: UserWarning: This overload of addcmul_ is deprecated:
addcmul_(Number value, Tensor tensor1, Tensor tensor2)
Consider using one of the following signatures instead:
addcmul_(Tensor tensor1, Tensor tensor2, *, Number value = 1) (Triggered internally at /pytorch/torch/csrc/utils/python_arg_parser.cpp:1661.)
exp_avg_sq.mul_(beta2).addcmul_(1 - beta2, grad, grad)
INFO:lightwood-3258:Loss of 9.051180630922318 with learning rate 0.0001
INFO:lightwood-3258:Loss of 9.014871209859848 with learning rate 0.0005
INFO:lightwood-3258:Loss of 8.969509482383728 with learning rate 0.001
INFO:lightwood-3258:Loss of 8.879052013158798 with learning rate 0.002
INFO:lightwood-3258:Loss of 8.788950502872467 with learning rate 0.003
INFO:lightwood-3258:Loss of 8.611965209245682 with learning rate 0.005
INFO:lightwood-3258:Loss of 8.195775926113129 with learning rate 0.01
INFO:lightwood-3258:Loss of 6.255893141031265 with learning rate 0.05
INFO:lightwood-3258:Found learning rate of: 0.05
/home/runner/work/lightwood/lightwood/lightwood/mixer/neural_ts.py:103: FutureWarning: `torch.cuda.amp.GradScaler(args...)` is deprecated. Please use `torch.amp.GradScaler('cuda', args...)` instead.
scaler = GradScaler()
INFO:lightwood-3258:Loss @ epoch 1: 0.5818348675966263
INFO:lightwood-3258:Loss @ epoch 2: 0.4797109067440033
[10:07:19] WARNING: ../src/learner.cc:339: No visible GPU is found, setting `gpu_id` to -1
[10:07:19] WARNING: ../src/learner.cc:339: No visible GPU is found, setting `gpu_id` to -1
[10:07:19] WARNING: ../src/learner.cc:339: No visible GPU is found, setting `gpu_id` to -1
[10:07:19] WARNING: ../src/learner.cc:339: No visible GPU is found, setting `gpu_id` to -1
[10:07:19] WARNING: ../src/learner.cc:339: No visible GPU is found, setting `gpu_id` to -1
[10:07:19] WARNING: ../src/learner.cc:339: No visible GPU is found, setting `gpu_id` to -1
INFO:lightwood-3258:Loss @ epoch 3: 0.48386093974113464
INFO:lightwood-3258:Loss @ epoch 4: 0.49511992931365967
INFO:lightwood-3258:Loss @ epoch 5: 0.39475560188293457
INFO:lightwood-3258:Loss @ epoch 6: 0.39592696726322174
INFO:lightwood-3258:Loss @ epoch 7: 0.3622782379388809
INFO:lightwood-3258:Loss @ epoch 8: 0.38170479238033295
INFO:lightwood-3258:Loss @ epoch 9: 0.5138543993234634
INFO:lightwood-3258:Loss @ epoch 10: 0.6360723078250885
/home/runner/work/lightwood/lightwood/lightwood/mixer/neural.py:335: FutureWarning: `torch.cuda.amp.GradScaler(args...)` is deprecated. Please use `torch.amp.GradScaler('cuda', args...)` instead.
scaler = GradScaler()
INFO:lightwood-3258:Loss @ epoch 1: 0.29868809472430835
INFO:lightwood-3258:Loss @ epoch 2: 0.30318967591632495
DEBUG:lightwood-3258: `fit_mixer` runtime: 0.48 seconds
INFO:lightwood-3258:Started fitting LGBM models for array prediction
INFO:lightwood-3258:Started fitting XGBoost model
[0] validation_0-rmse:42.76798
INFO:lightwood-3258:A single GBM iteration takes 0.1 seconds
INFO:lightwood-3258:Training XGBoost with 57023 iterations given 7127.987674713135 seconds constraint
[0] validation_0-rmse:42.76798
[1] validation_0-rmse:31.72661
[2] validation_0-rmse:24.49596
[3] validation_0-rmse:20.38592
[4] validation_0-rmse:18.09356
[5] validation_0-rmse:16.88080
[6] validation_0-rmse:16.21734
[7] validation_0-rmse:15.95640
[8] validation_0-rmse:15.80745
[9] validation_0-rmse:15.76428
[10] validation_0-rmse:15.89176
[11] validation_0-rmse:15.89176
[12] validation_0-rmse:15.87901
[13] validation_0-rmse:15.87505
[14] validation_0-rmse:16.06330
INFO:lightwood-3258:Started fitting XGBoost model
[0] validation_0-rmse:42.95930
INFO:lightwood-3258:A single GBM iteration takes 0.1 seconds
INFO:lightwood-3258:Training XGBoost with 57023 iterations given 7127.988974094391 seconds constraint
[0] validation_0-rmse:42.95930
[1] validation_0-rmse:32.27936
[2] validation_0-rmse:25.47815
[3] validation_0-rmse:21.37610
[4] validation_0-rmse:19.25243
[5] validation_0-rmse:18.03199
[6] validation_0-rmse:17.67706
[7] validation_0-rmse:17.57516
[8] validation_0-rmse:17.51227
[9] validation_0-rmse:17.51216
[10] validation_0-rmse:17.55192
[11] validation_0-rmse:17.56609
[12] validation_0-rmse:17.71702
[13] validation_0-rmse:17.75939
INFO:lightwood-3258:Started fitting XGBoost model
[0] validation_0-rmse:43.14000
INFO:lightwood-3258:A single GBM iteration takes 0.1 seconds
INFO:lightwood-3258:Training XGBoost with 57023 iterations given 7127.989117145538 seconds constraint
[0] validation_0-rmse:43.14000
[1] validation_0-rmse:32.50446
[2] validation_0-rmse:25.73040
[3] validation_0-rmse:22.16599
[4] validation_0-rmse:20.28726
[5] validation_0-rmse:19.46406
[6] validation_0-rmse:19.07306
[7] validation_0-rmse:19.00714
[8] validation_0-rmse:19.13990
[9] validation_0-rmse:19.12589
[10] validation_0-rmse:19.34977
[11] validation_0-rmse:19.43217
INFO:lightwood-3258:Started fitting XGBoost model
[0] validation_0-rmse:44.19079
INFO:lightwood-3258:A single GBM iteration takes 0.1 seconds
INFO:lightwood-3258:Training XGBoost with 57023 iterations given 7127.988581895828 seconds constraint
[0] validation_0-rmse:44.19079
[1] validation_0-rmse:34.13289
[2] validation_0-rmse:27.40621
[3] validation_0-rmse:23.82532
[4] validation_0-rmse:22.03399
[5] validation_0-rmse:21.07010
[6] validation_0-rmse:20.74813
[7] validation_0-rmse:20.81255
[8] validation_0-rmse:20.69303
[9] validation_0-rmse:20.71044
[10] validation_0-rmse:20.79641
[11] validation_0-rmse:20.78759
[12] validation_0-rmse:20.83998
INFO:lightwood-3258:Started fitting XGBoost model
[0] validation_0-rmse:44.24747
INFO:lightwood-3258:A single GBM iteration takes 0.1 seconds
INFO:lightwood-3258:Training XGBoost with 57023 iterations given 7127.98881816864 seconds constraint
[0] validation_0-rmse:44.24747
[1] validation_0-rmse:34.37446
[2] validation_0-rmse:27.88767
[3] validation_0-rmse:24.63817
[4] validation_0-rmse:22.84209
[5] validation_0-rmse:22.35045
[6] validation_0-rmse:22.11300
[7] validation_0-rmse:22.16132
[8] validation_0-rmse:22.21348
[9] validation_0-rmse:22.10747
[10] validation_0-rmse:22.20352
[11] validation_0-rmse:22.25761
[12] validation_0-rmse:22.25308
[13] validation_0-rmse:22.31415
[14] validation_0-rmse:22.31000
INFO:lightwood-3258:Started fitting XGBoost model
[0] validation_0-rmse:44.48913
INFO:lightwood-3258:A single GBM iteration takes 0.1 seconds
INFO:lightwood-3258:Training XGBoost with 57023 iterations given 7127.987869024277 seconds constraint
[0] validation_0-rmse:44.48913
[1] validation_0-rmse:34.69001
[2] validation_0-rmse:28.87323
[3] validation_0-rmse:25.32567
[4] validation_0-rmse:23.09943
[5] validation_0-rmse:22.12203
[6] validation_0-rmse:21.71523
[7] validation_0-rmse:21.70934
[8] validation_0-rmse:21.74380
[9] validation_0-rmse:21.61157
[10] validation_0-rmse:21.73507
[11] validation_0-rmse:21.84587
[12] validation_0-rmse:21.78099
[13] validation_0-rmse:21.68890
DEBUG:lightwood-3258: `fit_mixer` runtime: 0.48 seconds
INFO:dataprep_ml-3258:Ensembling the mixer
INFO:lightwood-3258:Mixer: NeuralTs got accuracy: 0.875
WARNING:lightwood-3258:This model does not output probability estimates
INFO:lightwood-3258:Mixer: XGBoostArrayMixer got accuracy: 0.869
INFO:lightwood-3258:Picked best mixer: NeuralTs
DEBUG:lightwood-3258: `fit` runtime: 1.01 seconds
INFO:dataprep_ml-3258:[Learn phase 7/8] - Ensemble analysis
INFO:dataprep_ml-3258:Analyzing the ensemble of mixers
INFO:lightwood-3258:The block ICP is now running its analyze() method
INFO:lightwood-3258:The block ConfStats is now running its analyze() method
INFO:lightwood-3258:The block AccStats is now running its analyze() method
/opt/hostedtoolcache/Python/3.9.21/x64/lib/python3.9/site-packages/sklearn/metrics/_classification.py:409: UserWarning: A single label was found in 'y_true' and 'y_pred'. For the confusion matrix to have the correct shape, use the 'labels' parameter to pass all known labels.
warnings.warn(
INFO:lightwood-3258:The block PermutationFeatureImportance is now running its analyze() method
WARNING:lightwood-3258:Block 'PermutationFeatureImportance' does not support time series nor text encoding, skipping...
DEBUG:lightwood-3258: `analyze_ensemble` runtime: 0.17 seconds
INFO:dataprep_ml-3258:[Learn phase 8/8] - Adjustment on validation requested
INFO:dataprep_ml-3258:Updating the mixers
/home/runner/work/lightwood/lightwood/lightwood/mixer/neural.py:335: FutureWarning: `torch.cuda.amp.GradScaler(args...)` is deprecated. Please use `torch.amp.GradScaler('cuda', args...)` instead.
scaler = GradScaler()
/opt/hostedtoolcache/Python/3.9.21/x64/lib/python3.9/site-packages/torch/amp/grad_scaler.py:132: UserWarning: torch.cuda.amp.GradScaler is enabled, but CUDA is not available. Disabling.
warnings.warn(
INFO:lightwood-3258:Loss @ epoch 1: 0.29626286526521045
INFO:lightwood-3258:Loss @ epoch 2: 0.2954987535874049
INFO:lightwood-3258:Updating array of LGBM models...
INFO:lightwood-3258:XGBoost mixer does not have a `partial_fit` implementation
INFO:lightwood-3258:XGBoost mixer does not have a `partial_fit` implementation
INFO:lightwood-3258:XGBoost mixer does not have a `partial_fit` implementation
INFO:lightwood-3258:XGBoost mixer does not have a `partial_fit` implementation
INFO:lightwood-3258:XGBoost mixer does not have a `partial_fit` implementation
INFO:lightwood-3258:XGBoost mixer does not have a `partial_fit` implementation
DEBUG:lightwood-3258: `adjust` runtime: 0.1 seconds
DEBUG:lightwood-3258: `learn` runtime: 1.53 seconds
Predict
Once the predictor has trained, we can use it to generate 6-month forecasts for each of the test set data points:
[7]:
forecasts = predictor.predict(test)
INFO:dataprep_ml-3258:[Predict phase 1/4] - Data preprocessing
/tmp/6256c645da02262e865e7c1cade757303a6ff5b9cf28010817428972390937438.py:587: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data[col] = [None] * len(data)
INFO:dataprep_ml-3258:Cleaning the data
/opt/hostedtoolcache/Python/3.9.21/x64/lib/python3.9/site-packages/dataprep_ml/cleaners.py:163: UserWarning: The argument 'infer_datetime_format' is deprecated and will be removed in a future version. A strict version of it is now the default, see https://pandas.pydata.org/pdeps/0004-consistent-to-datetime-parsing.html. You can safely remove this argument.
result = pd.to_datetime(element,
INFO:dataprep_ml-3258:Transforming timeseries data
DEBUG:lightwood-3258: `preprocess` runtime: 0.02 seconds
INFO:dataprep_ml-3258:[Predict phase 2/4] - Feature generation
INFO:dataprep_ml-3258:Featurizing the data
DEBUG:lightwood-3258: `featurize` runtime: 0.01 seconds
INFO:dataprep_ml-3258:[Predict phase 3/4] - Calling ensemble
DEBUG:lightwood-3258: `_timed_call` runtime: 0.09 seconds
INFO:dataprep_ml-3258:[Predict phase 4/4] - Analyzing output
INFO:lightwood-3258:The block ICP is now running its explain() method
INFO:lightwood-3258:The block ConfStats is now running its explain() method
INFO:lightwood-3258:ConfStats.explain() has not been implemented, no modifications will be done to the data insights.
INFO:lightwood-3258:The block AccStats is now running its explain() method
INFO:lightwood-3258:AccStats.explain() has not been implemented, no modifications will be done to the data insights.
INFO:lightwood-3258:The block PermutationFeatureImportance is now running its explain() method
INFO:lightwood-3258:PermutationFeatureImportance.explain() has not been implemented, no modifications will be done to the data insights.
DEBUG:lightwood-3258: `explain` runtime: 0.09 seconds
DEBUG:lightwood-3258: `predict` runtime: 0.22 seconds
Let’s check how a single row might look:
[8]:
forecasts.iloc[[10]]
[8]:
| original_index | prediction | order_Month | confidence | lower | upper | anomaly | prediction_sum | lower_sum | upper_sum | confidence_mean | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 10 | [50.51358374451768, 53.78975402923053, 51.0303... | [-273628800.0, -270950400.0, -268272000.0, -26... | [0.79, 0.02, 0.9991, 0.9991, 0.9991, 0.9991] | [30.14139795091352, 32.97332333016865, 0.0, 0.... | [70.88576953812185, 74.60618472829242, 137.289... | False | 294.494088 | 0.0 | 209.075865 | 0.801067 |
You’ll note that the point prediction has associated lower and upper bounds that are a function of the estimated confidence the model has on its own output. Apart from this, order_Month yields the timestamps of each prediction, the anomaly tag will let you know if the observed value falls outside of the predicted region.
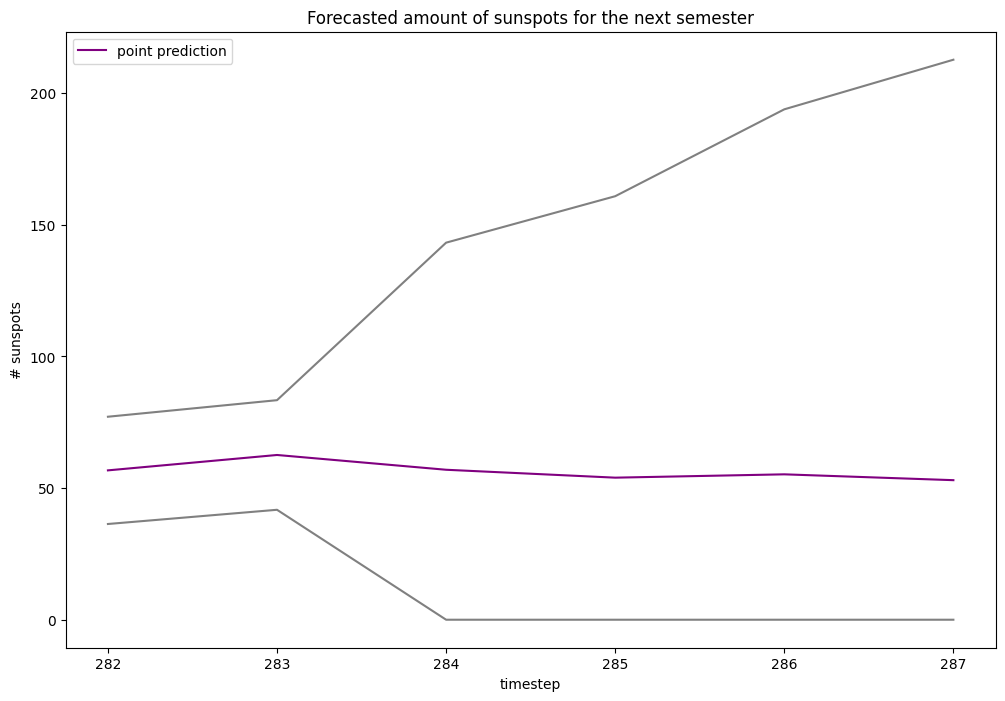
Visualizing a forecast
Okay, time series are much easier to appreciate through plots. Let’s make one:
NOTE: We will use matplotlib to generate a simple plot of these forecasts. If you want to run this notebook locally, you will need to pip install matplotlib for the following code to work.
[9]:
import matplotlib.pyplot as plt
[10]:
plt.figure(figsize=(12, 8))
plt.plot([None for _ in range(forecasts.shape[0])] + forecasts.iloc[-1]['prediction'], color='purple', label='point prediction')
plt.plot([None for _ in range(forecasts.shape[0])] + forecasts.iloc[-1]['lower'], color='grey')
plt.plot([None for _ in range(forecasts.shape[0])] + forecasts.iloc[-1]['upper'], color='grey')
plt.xlabel('timestep')
plt.ylabel('# sunspots')
plt.title("Forecasted amount of sunspots for the next semester")
plt.legend()
plt.show()
Conclusion
In this tutorial, we have gone through how you can train a machine learning model with Lightwood to produce forecasts for a univariate time series task.
There are additional parameters to further customize your timeseries settings and/or prediction insights, so be sure to check the rest of the documentation.